Data nodes
Resources: Data nodes
This section is part of a series on the topic of data nodes.
Docs:
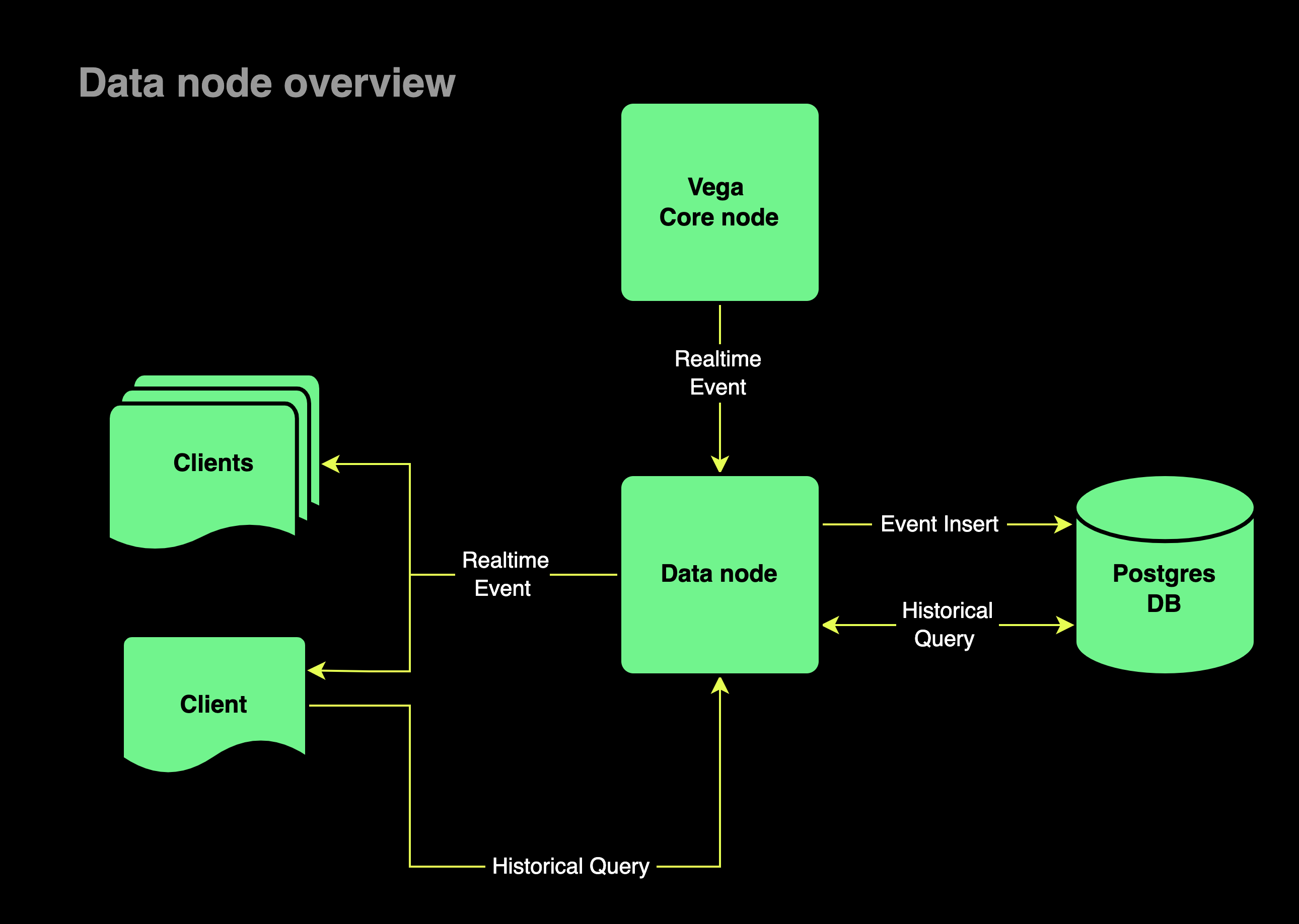
Protocol users need to see and interact with data, such as price history, market changes, validator scores, and more. While the core emits events when states change, it does not store the data about those events. The core is responsible for processing transactions for the chain and ensuring correctness.
Any processing that isn't required to make the next block is done by the data node. The data node collects, stores, and relates the events, and makes them available through API queries that can be used directly, and through dapps and other tools.
Data node stores information in a PostgreSQL database, and augments the data (by linking order and party data together, for example) to provide richer, more informative APIs. Those functions require extra processing that is best kept separate from running the blockchain so as not to hinder its performance.
Diagram: Data node structure
Running a data node
Data nodes can be set up and run by anyone who wants to collect and store network event data and make it available. Data nodes can be publicly available for use by dApps, or they can be used privately.
Running your own data node would be useful for building a complex integration, or if you don't want to rely on a third-party data node. Another reason for running a data node would be to track data at the granularity and frequency you want.
A data node can be run privately or publicly. Public data nodes help support the Vega community and users by allowing them to connect and reliably see live and historical data.
Setting up a data node requires configuring and using the Vega data node software.
Wallet transactions
The Vega Wallet is the conduit for approving and sending transactions from the user to the core. The data node exposes the exact same endpoints as the core node, and so it can act as a proxy for the core node.
When the wallet sends a transaction request to a data node, the data node ingests the request and directly forwards it to the core node it is connected to. That node, whether or not it is a consensus validator, will then send the transaction to the network. The consensus validators will then decide on the validity of the transaction and execute it.
Data structure
In order to provide reliable, indexable data, the data node stores information with a specific structure and set of standard details.
Each chunk of data contains an event ID that identifies the core event that created it, and the block in which the event was created. An event is emitted whenever the blockchain time updates, and each chunk of data stored is labelled with the timestamp.
Data node code ↗: See how the data node service is built.
Types of data stored
The data node listens to the event stream and provides access not only to the raw data, but also links relevant information together, such as an order and the party ID that placed the order, or the order, the party and the positions that filled that order, so that queries like "show orders that were placed by Party Y" can be done.
Other types of data that the data node makes queryable include (but are not limited to):
- Validator node details and history: Current status and changes to stake and nominations, details per epoch, and performance metrics.
- Staking rewards per epoch per Vega ID of validators/tokenholders, including the asset, amount, percentage of total and timestamp
- Governance proposals: All proposals submitted, the 'yes' and 'no' votes, and the parameter changes proposed
- Trading related data: Prices current and historical such as best bid/ask, mid, mark price; open interest, trade price/volume, closeout trades, loss socialisation events, position mark-to-market events; indicative auction uncrossing price and volume
- Market lifecycle events: Auction start, end, reason for entering, type of auction; settlement, trading terminated
- Liquidity provision data: liquidity commitment submissions, changes in equity-like share, target stake, supplied stake
- Risk data: Margin level events, Model parameter changes, Risk factor changes, Price monitoring bound setting changes, Price monitoring bounds
- Candle data: Data that corresponds to trades during a certain time period: first trade, highest traded price, lowest traded price
APIs
For clients to communicate with data nodes, the protocol exposes a set of APIs and methods for reading data. Currently there are three protocols to communicate with the data node APIs: GraphQL, gRPC, and REST.
Querying for data provided through the APIs is the easiest way to access the information that the data node provides, whether that's directly, or by using a dApp/user interface.
If you are running your own data node, you can choose to enable any/all of the protocols, to tailor to your needs. Data nodes run by validators are expected to provide GraphQL, gRPC, and REST, and reliably serve data.
Database
The data node relies on PostgreSQL and IPFS. Postgres, an open source, relational database that supports relational and non-relational queries, is used to store and provide the data.
IPFS is used to share decentralised history segments across a data node's network.
- About PostgreSQL ↗: Read about PostgreSQL and explore the documentation.
- About IPFS ↗: Get familiar with IPFS.
Connect directly to database
It's possible to connect directly to the Postgres database of a data node without running a data node yourself, if the data node you're using allows it. You'll need the connection details from the data node operator, such as the relevant address, username and password in order to connect directly to that node's database.
Alternatively, you can run your own data node and use decentralised history to pull existing data into your new database, or start fresh.
PostgreSQL database schemas are liable to change without warning and without deprecation.
Data retention
A data node's data retention time allows data node operator to store historical data for specific amounts of time.
Data types are grouped into categories, and the retention time for each type can be changed in the data node's config.toml file. You can configure a data node so that all data older than any time period (e.g. 1m, 1h, 1h:22m:32s, 1 month) is deleted, or extend the default times for the retention mode you choose.
Some data can be saved in detail, and in a less-detailed sampling. Take balances, for example: In addition to saving every balance change, the conflated balances keep a sample of a balance from once every hour. This allows the data node to have data for a long period of time, but taking up less space than saving every balance change over a year.
The data node code's configuration includes a set of default retention time frames. Those time frames have been defined with an individual trader that wants to run their own data node, for their own use, in mind. A public data node that's intended to support querying archival information will need much longer data retention time frames.
Whenever a data node starts up, the existing retention policy for each data type is output in the logs.
Data retention profiles
When starting a data node, your chosen retention profile will be applied. After initialisation, it's possible to change the retention profile by changing the retention period setting in the configuration file.
The three retention profiles are:
- Archive (default): The node retains all data and is the expected and only recommended retention profile for a public data node.
- Minimal: The node retains only data about a network's current state. This can be useful for private data nodes that will be used to serve live data and stream changing states.
- Conservative: The node does not retain all data and per-table rentention is set based on the defaults below. This can be useful for private data nodes who may want a customise their per-table data rentention based on their specific usecase.
Conservative data node retention times
| Data type | Default retention |
|---|---|
| Balances (fine-grained) | 7 days |
| Balances (conflated) | 1 year |
| Deposits | 1 year |
| Withdrawals | 1 year |
| Network checkpoints | 7 days |
| Delegations | 7 days |
| Ledger entries | 6 months |
| Orders | 1 month |
| Trades | 1 year |
| Trades 1 minute candle | 1 month |
| Trades 5 minute candle | 1 month |
| Trades 15 minute candle | 1 month |
| Trades 1 hour candle | 1 year |
| Trades 6 hour candle | 1 year |
| Trades 1 day candle | 1 year |
| Markets | 1 year |
| Market data | 7 days |
| Margin levels | 7 days |
| Margin levels (conflated) | 1 year |
| Positions | 7 days |
| Conflated positions | 1 year |
| Liquidity provisions | 1 day |
| Blocks | Equal to longest retention across all data types |
Change retention times
From version 0.68, retention policy for any data type can be overridden by creating an entry in the config file, under the SQLStore section, as seen below. Once you change the retention policy, you will need to restart your data node.
[SQLStore]
[[SQLStore.RetentionPolicies]]
HypertableOrCaggName = "balances"
DataRetentionPeriod = "7 days"
[[SQLStore.RetentionPolicies]]
HypertableOrCaggName = "checkpoints"
DataRetentionPeriod = "7 days"
Hypertable chunk intervals
The data node uses hypertables ↗ to store data. Hypertables are a TimescaleDB feature that allows you to store large amounts of time-series data in a more efficient way than a regular PostgreSQL table.
The pre-determined default values are applied when the database migrations. They are generally set to 1 day. The chunk interval determines how much data is stored in each chunk and affects the amount of RAM used by the database, as recent chunks are kept in memory in order to make querying faster.
Change chunk intervals
From version 0.70, the chunk interval for any hypertable can be overridden by creating an entry in the config file, under the SQLStore section, as seen below. Once you change the chunk interval, you will need to restart your data node. The new chunk interval will be applied starting from the next chunk. Existing chunks will not be affected.
[SQLStore]
[[SQLStore.ChunkIntervals]]
HypertableOrCaggName = "balances"
ChunkInterval = "1 day"
[[SQLStore.ChunkIntervals]]
HypertableOrCaggName = "checkpoints"
ChunkInterval = "1 day"
Network history
The daily addition of gigabites of core event data to the data node make it infeasible for a new data node to replay all blocks from the first block. Instead, new nodes can use a feature called network history to recreate the history quickly and get into a state to be able to consume new blocks.
History segments produced on every node for a given block span are identical, such that the IPFS content IDs of the segment are the same across all nodes. This means there's no need to upload data between nodes, as each node produces history segments, and thus can be a source of history segments.
When a new node joins the network and requests a history segment for a given IPFS content ID, the provision of data to the node is shared across all other nodes in the network. The data node software also supports pulling all available historical data asynchronously once the newly joined data node has loaded the latest history segment.
A network history segment is created every snapshot interval. It gets the interval's worth of data from the PostgreSQL database to create the history segment, without blocking event processing. The data node then publishes it to the network's IPFS swarm, thus making it available to all other current and future data nodes (per network).
Readme: Network history: How to use network history